Technology - Google News |
- Samsung Galaxy S21 Ultra S Pen support confirmed by FCC - The Verge
- Mastering Atari, Go, chess and shogi by planning with a learned model - Nature.com
- Facebook Employees Criticize Campaign Against Apple in Leaked Comments - MacRumors
| Samsung Galaxy S21 Ultra S Pen support confirmed by FCC - The Verge Posted: 23 Dec 2020 02:21 AM PST An FCC listing confirms that Samsung's S Pen stylus can be used with the company's upcoming flagship Galaxy S21 Ultra phone. The confirmation, first discovered by Android Authority, comes in a test report for model number SMG998B. The discovery lends clarity to recent statements from Samsung mobile president TM Roh, who said that some of the "most well-loved features" of the Galaxy Note will be coming to other Samsung devices in 2021. The FCC test report explicitly describes an EUT (Equipment Under Test) device that can be used with an S Pen in both hover and click modes. "The EUT can also used with a stylus device (S Pen). The EUT operates with the S Pen in two different inductive coupling modes of S Pen motion detection (Hover and Click) operating in the range of 0.53 –0.6MHz." :format(webp):no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/22192788/s21_fcc_listing_uwb_and_s_pen.jpg) The listing also confirms wireless power transfer (to charge things like the upcoming Galaxy Buds Pro earbuds), Wi-Fi 6E, and UWB on the yet to be announced Galaxy S21 Ultra. Last week Roh also said that Samsung planned to do more with ultra-wideband in 2021 with help from partners, like using UWB to locate objects or your family pet, open doors, and personalize car experiences. Everything should become clear at the upcoming Samsung event in January, presumably on Thursday the 14th if rumors hold. |
| Mastering Atari, Go, chess and shogi by planning with a learned model - Nature.com Posted: 23 Dec 2020 08:10 AM PST 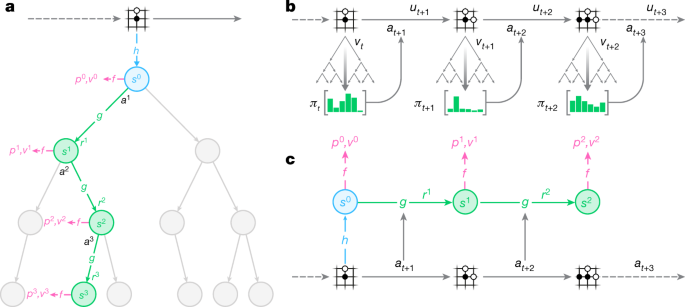 Campbell, M., Hoane, A. J. Jr & Hsu, F.-h. Deep Blue. Artif. Intell. 134, 57–83 (2002). Silver, D. et al. Mastering the game of Go with deep neural networks and tree search. Nature 529, 484–489 (2016). Bellemare, M. G., Naddaf, Y., Veness, J. & Bowling, M. The arcade learning environment: an evaluation platform for general agents. J. Artif. Intell. Res. 47, 253–279 (2013). Machado, M. et al. Revisiting the arcade learning environment: evaluation protocols and open problems for general agents. J. Artif. Intell. Res. 61, 523–562 (2018). Silver, D. et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 362, 1140–1144 (2018). Schaeffer, J. et al. A world championship caliber checkers program. Artif. Intell. 53, 273–289 (1992). Brown, N. & Sandholm, T. Superhuman AI for heads-up no-limit poker: Libratus beats top professionals. Science 359, 418–424 (2018). Moravčík, M. et al. Deepstack: expert-level artificial intelligence in heads-up no-limit poker. Science 356, 508–513 (2017). Vlahavas, I. & Refanidis, I. Planning and Scheduling Technical Report (EETN, 2013). Segler, M. H., Preuss, M. & Waller, M. P. Planning chemical syntheses with deep neural networks and symbolic AI. Nature 555, 604–610 (2018). Sutton, R. S. & Barto, A. G. Reinforcement Learning: An Introduction 2nd edn (MIT Press, 2018). Deisenroth, M. & Rasmussen, C. PILCO: a model-based and data-efficient approach to policy search. In Proc. 28th International Conference on Machine Learning, ICML 2011 465–472 (Omnipress, 2011). Heess, N. et al. Learning continuous control policies by stochastic value gradients. In NIPS'15: Proc. 28th International Conference on Neural Information Processing Systems Vol. 2 (eds Cortes, C. et al.) 2944–2952 (MIT Press, 2015). Levine, S. & Abbeel, P. Learning neural network policies with guided policy search under unknown dynamics. Adv. Neural Inf. Process. Syst. 27, 1071–1079 (2014). Hafner, D. et al. Learning latent dynamics for planning from pixels. Preprint at https://arxiv.org/abs/1811.04551 (2018). Kaiser, L. et al. Model-based reinforcement learning for atari. Preprint at https://arxiv.org/abs/1903.00374 (2019). Buesing, L. et al. Learning and querying fast generative models for reinforcement learning. Preprint at https://arxiv.org/abs/1802.03006 (2018). Espeholt, L. et al. IMPALA: scalable distributed deep-RL with importance weighted actor-learner architectures. In Proc. International Conference on Machine Learning, ICML Vol. 80 (eds Dy, J. & Krause, A.) 1407–1416 (2018). Kapturowski, S., Ostrovski, G., Dabney, W., Quan, J. & Munos, R. Recurrent experience replay in distributed reinforcement learning. In International Conference on Learning Representations (2019). Horgan, D. et al. Distributed prioritized experience replay. In International Conference on Learning Representations (2018). Puterman, M. L. Markov Decision Processes: Discrete Stochastic Dynamic Programming 1st edn (John Wiley & Sons, 1994). Coulom, R. Efficient selectivity and backup operators in Monte-Carlo tree search. In International Conference on Computers and Games 72–83 (Springer, 2006). Wahlström, N., Schön, T. B. & Deisenroth, M. P. From pixels to torques: policy learning with deep dynamical models. Preprint at http://arxiv.org/abs/1502.02251 (2015). Watter, M., Springenberg, J. T., Boedecker, J. & Riedmiller, M. Embed to control: a locally linear latent dynamics model for control from raw images. In NIPS'15: Proc. 28th International Conference on Neural Information Processing Systems Vol. 2 (eds Cortes, C. et al.) 2746–2754 (MIT Press, 2015). Ha, D. & Schmidhuber, J. Recurrent world models facilitate policy evolution. In NIPS'18: Proc. 32nd International Conference on Neural Information Processing Systems (eds Bengio, S. et al.) 2455–2467 (Curran Associates, 2018). Gelada, C., Kumar, S., Buckman, J., Nachum, O. & Bellemare, M. G. DeepMDP: learning continuous latent space models for representation learning. Proc. 36th International Conference on Machine Learning: Volume 97 of Proc. Machine Learning Research (eds Chaudhuri, K. & Salakhutdinov, R.) 2170–2179 (PMLR, 2019). van Hasselt, H., Hessel, M. & Aslanides, J. When to use parametric models in reinforcement learning? Preprint at https://arxiv.org/abs/1906.05243 (2019). Tamar, A., Wu, Y., Thomas, G., Levine, S. & Abbeel, P. Value iteration networks. Adv. Neural Inf. Process. Syst. 29, 2154–2162 (2016). Silver, D. et al. The predictron: end-to-end learning and planning. In Proc. 34th International Conference on Machine Learning Vol. 70 (eds Precup, D. & Teh, Y. W.) 3191–3199 (JMLR, 2017). Farahmand, A. M., Barreto, A. & Nikovski, D. Value-aware loss function for model-based reinforcement learning. In Proc. 20th International Conference on Artificial Intelligence and Statistics: Volume 54 of Proc. Machine Learning Research (eds Singh, A. & Zhu, J) 1486–1494 (PMLR, 2017). Farahmand, A. Iterative value-aware model learning. Adv. Neural Inf. Process. Syst. 31, 9090–9101 (2018). Farquhar, G., Rocktaeschel, T., Igl, M. & Whiteson, S. TreeQN and ATreeC: differentiable tree planning for deep reinforcement learning. In International Conference on Learning Representations (2018). Oh, J., Singh, S. & Lee, H. Value prediction network. Adv. Neural Inf. Process. Syst. 30, 6118–6128 (2017). Krizhevsky, A., Sutskever, I. & Hinton, G. E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 25, 1097–1105 (2012). He, K., Zhang, X., Ren, S. & Sun, J. Identity mappings in deep residual networks. In 14th European Conference on Computer Vision 630–645 (2016). Hessel, M. et al. Rainbow: combining improvements in deep reinforcement learning. In Thirty-Second AAAI Conference on Artificial Intelligence (2018). Schmitt, S., Hessel, M. & Simonyan, K. Off-policy actor-critic with shared experience replay. Preprint at https://arxiv.org/abs/1909.11583 (2019). Azizzadenesheli, K. et al. Surprising negative results for generative adversarial tree search. Preprint at http://arxiv.org/abs/1806.05780 (2018). Mnih, V. et al. Human-level control through deep reinforcement learning. Nature 518, 529–533 (2015). Open, A. I. OpenAI five. OpenAI https://blog.openai.com/openai-five/ (2018). Vinyals, O. et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning. Nature 575, 350–354 (2019). Jaderberg, M. et al. Reinforcement learning with unsupervised auxiliary tasks. Preprint at https://arxiv.org/abs/1611.05397 (2016). Silver, D. et al. Mastering the game of Go without human knowledge. Nature 550, 354–359 (2017). Kocsis, L. & Szepesvári, C. Bandit based Monte-Carlo planning. In European Conference on Machine Learning 282–293 (Springer, 2006). Rosin, C. D. Multi-armed bandits with episode context. Ann. Math. Artif. Intell. 61, 203–230 (2011). Schadd, M. P., Winands, M. H., Van Den Herik, H. J., Chaslot, G. M.-B. & Uiterwijk, J. W. Single-player Monte-Carlo tree search. In International Conference on Computers and Games 1–12 (Springer, 2008). Pohlen, T. et al. Observe and look further: achieving consistent performance on Atari. Preprint at https://arxiv.org/abs/1805.11593 (2018). Schaul, T., Quan, J., Antonoglou, I. & Silver, D. Prioritized experience replay. In International Conference on Learning Representations (2016). Cloud TPU. Google Cloud https://cloud.google.com/tpu/ (2019). Coulom, R. Whole-history rating: a Bayesian rating system for players of time-varying strength. In International Conference on Computers and Games 113–124 (2008). Nair, A. et al. Massively parallel methods for deep reinforcement learning. Preprint at https://arxiv.org/abs/1507.04296 (2015). Lanctot, M. et al. OpenSpiel: a framework for reinforcement learning in games. Preprint at http://arxiv.org/abs/1908.09453 (2019). |
| Facebook Employees Criticize Campaign Against Apple in Leaked Comments - MacRumors Posted: 23 Dec 2020 03:11 AM PST Amid a barrage of public attacks on Apple from Facebook over privacy measures, Facebook employees have expressed their displeasure with the direction of the campaign in comments obtained by BuzzFeed News.
/article-new/2020/12/Apple-vs-Facebook-feature.jpg?lossy) Last week, Facebook launched a campaign in print newspapers explaining that it was "standing up to Apple for small businesses everywhere," and created a website encouraging people to "Speak Up for Small Businesses." Facebook argues that Apple's privacy changes in iOS 14, which give users the option to opt-out of ad tracking, will harm small businesses that see increased sales from personalized ads. However, some Facebook employees are reportedly complaining about what they perceived to be a self-serving campaign. BuzzFeed News obtained internal comments from one of Facebook's private message boards and audio of a presentation to Facebook workers, revealing that there is discontentment among employees about the angle used to attack Apple's privacy changes. One Facebook engineer, in response to an internal post about the campaign from Facebook's advertising chief Dan Levy, said:
Ahead of an internal meeting to explain the rationale of the campaign against Apple, Facebook employees asked and voted up several questions that focused on the consequences of the campaign on Facebook's public image. The most popular questions asked reportedly all expressed skepticism or concern:
In response, Facebook vice president of product marketing Graham Mudd said that the company has been "really clear" that Apple's changes do "have a financial impact on us," in addition to small businesses:
Following the presentation, many Facebook employees were apparently unconvinced. Some did not understand how Apple's changes would negatively affect small businesses, while one highlighted that Apple's privacy changes also prevent "malicious actors" from tracking people:
The same employee launched a scathing attack on Levy's post, accompanied by a popular meme with the text "Are we the baddies?"
Other critics suggested that Facebook incentivizes opting-in to ad tracking in a positive campaign rather than attacking the notion of a choice to opt-in or out. Levy responded to criticisms explaining that the campaign was simply "not about our business model."
Other comments from employees highlighted that the spirited defense of small businesses was hypocritical because Facebook has repeatedly disabled the ad accounts of small business advertisers by mistake and increasingly uses automated customer support, leading to a plethora of public complaints from small businesses:
Facebook spokesperson Ashley Zandy responded to BuzzFeed News, insisting that the stories of small businesses are Facebook's priority:
Following the launch of the campaign, the Electronic Frontier Foundation (EFF), a non-profit organization that defends civil liberties in the digital world, called Facebook's criticisms of tracking-related privacy measures "laughable." |
| You are subscribed to email updates from Technology - Latest - Google News. To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google, 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States | |
This post have 0 komentar
EmoticonEmoticon